机器学习——正则化
问题:过拟合
算法训练结束后可能会产生两种让人不想面对的结果,一种是欠拟合,一种是过拟合。需要注意二者针对的对象都是训练数据,再结合名字就非常容易理解这两个名字的意思了。
欠拟合:即使是在训练数据上都存在较大的误差。
过拟合:在训练数据上误差非常小甚至没有误差,过度的拟合了训练数据以至于失去了数据整体上的趋势不能很好的用在真实数据上。
过拟合产生的原因主要有两个,过多的特征参数,过少的训练数据。
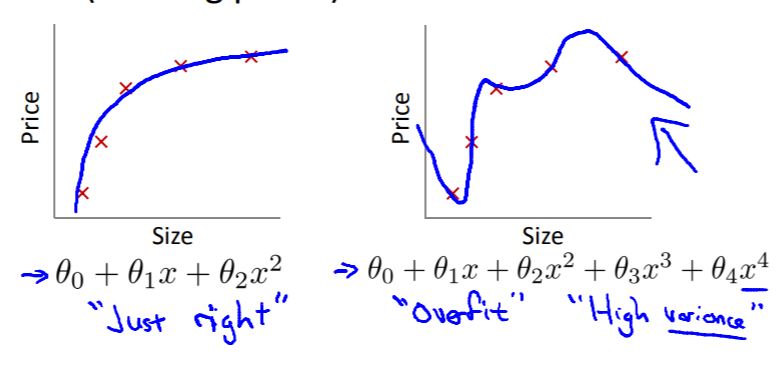
过多的特征参数:选择的参数中存在一些对结果没有什么贡献,捣乱居多的特征。(例如房价预测中的3阶和4阶项)
过少的训练数据:在特征参数选择过多的情况下训练数据还少了,训练起来就抓不住主要方向了就开始乱搞了。
解决方法也主要是针对这两个原因来的,其中效果又好操作起来又简单的就是增加更多高质量的训练数据了,Google不是有句话叫做”更多的数据胜过更好的算法“吗?自己感觉训练数据的增加也是现在AI技术逐步走入生活的原因,因为互联网的发展为算法提供了海量的数据作为养料。但是训练数据的获取也不是那么的容易的,特别是高质量的训练数据。
所以大佬们瞄向了另外一个原因双管齐下,就不信它还过拟合。对症下药乱七八糟的特征多了那就去掉一些没什么用的特征,具体的方法是课程中提到的Model selection algorithm。之后会学那就之后再来更新吧。直接舍弃一些特征简单粗暴,但是按照吴老师的话来说在你舍弃一些特征的同时也舍弃了一部分信息,而且这些特征收集起来也不容易舍不得怎么办。这个时候就轮到正则化方法(regularization)登场了。
方法之一:正则化
当参数太多的情况下因为搞不清楚哪个参数和结果的关联度比较小,所以正则化缩小每一个参数θ,这样得到的模型更为简单平滑。为什么参数θ小模型就布局平滑呢?平滑的模型其导数的绝对值一般来说较小,过拟合的模型一般来说比较曲折如下图所示:
而对于线性模型来说导数就是模型的参数本身,因此,减小参数绝对值就可以达到减小导数绝对值的效果,即可达到平滑模型、防止过拟合的效果。最终课程中得到的代价函数如下所示:
2018年11月1日更新
为什么模型本身光滑一点,模型的泛化能力会更好一些呢?可以这样思考,我们在模型训练完成之后使用对结果进行预测,我们假设正确的模型是如下所示的:
而我们收集到的是带有噪声的:
可以看到如果W太大的话那么噪声就也被放大了,erro就变大了,模型的泛化能力就没那么好了。
公式右边的即为正则项,这个公式中使用的是范数作为正则项,既然有那么肯定就会有和了,具体的含义和区别可以参考参考资料[1]中的高票回答。除了范数可以作为正则项,还存在其他的正则项,但是目前还不了解,学习了之后再更新吧。
参考资料:
机器学习中常常提到的正则化是什么意思? [1]
理解正则化项L1和L2的区别[2]
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 协议 ,转载请注明出处!