机器学习笔记——线性回归
在写线性回归的笔记前,我觉得有必要介绍一下机器学习的概念和现在机器学习的大体的一些架构和概念。
机器学习的定义
套用coursera上的说法。对于机器学习,并没有一个一致认同的定义,一个比较古老的定义是由Arthur Samuel在1959
年给出的:
“机器学习研究的是如何赋予计算机在没有被明确编程的情况下仍能够学习的能力。
(Field of study that fives computers the ability to learn without being explicitly
programmed.)”
Samuel 编写了一个跳棋游戏的程序,并且让这个程序和程序自身玩了几万局跳棋游戏,并且
记录下来棋盘上的什么位置可能会导致怎样的结果,随着时间的推移,计算机学会了棋盘上的
哪些位置可能会导致胜利,并且最终战胜了设计程序的 Samuel.
另一个比较现代且形式化的定义是由 Tom Mitchell 在 1998 年给出的:
“对于某个任务 T 和表现的衡量 P,当计算机程序在该任务 T 的表现上,经过 P 的衡量,
随着经验 E 而增长,我们便称计算机程序能够通过经验 E 来学习该任务。( computer program
is said to learn from experience E with respect to some task T and some performance
measure P, if its performance on T, as measured by P, improves with experience E.)”
在跳棋游戏的例子中,任务 T 是玩跳棋游戏,P 是游戏的输赢,E 则是一局又一局的游戏。
一些机器学习的应用举例:
- 数据库挖掘
- 一些无法通过手动编程来编写的应用:如自然语言处理,计算机视觉
- 一些自助式的程序:如推荐系统
- 理解人类是如何学习的
机器学习的架构
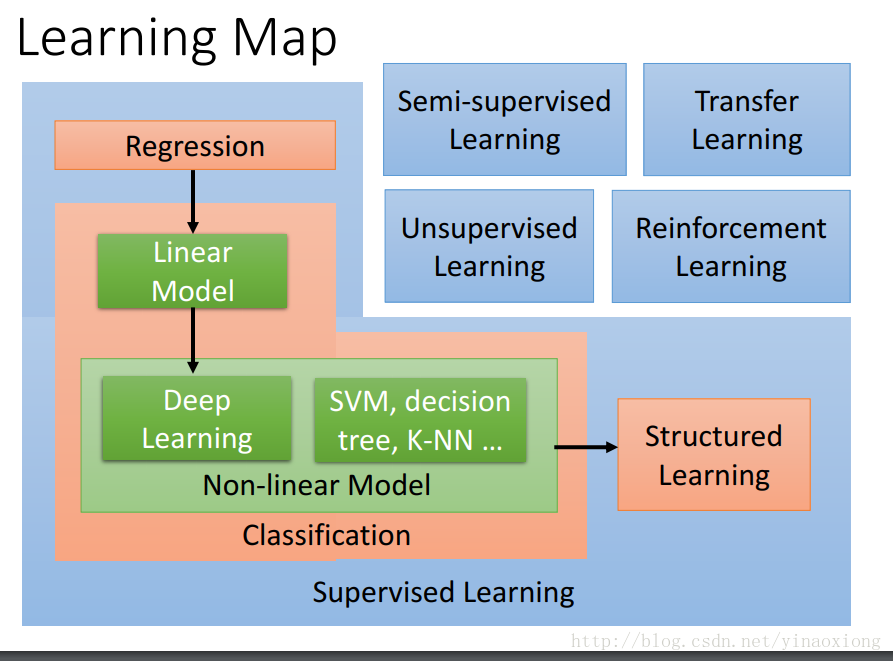
我觉得关于这方面李弘毅教授的机器学习的课中讲的非常的好,这是课程的主页感兴趣的可以去看一下http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML16.html。我们时常听到Supervise Learning,Unsupervised Learning…等等之类的名词,并且也理解其中的意思。但是在没看到这张图之前我对于这些概念其实还是不是特别的清楚。
- 在这个图中蓝色的部分和其中的名词代表的是我们已知的数据。举个例子说,Supervised Learning代表我们拥有数据以及以及这些数据的标签,而Reinforcenment Learning是有部分有限的带有标签的数据,和一个判别模型,Reinforcement Learning一个出门的例子是alpha Go。工程师们先用人类以前下过的棋谱来训练它,这个写棋谱就是带标签的数据,但是棋谱的数量是有限的所以为了更一步提高,就让不同的alpha Go的副本自我博弈,然后根据胜负这个结果来判别,让机器内部自我调整。在这里难道工程师不想用Supervised Learning吗?但是由于棋谱的数量限制所以根据实际的情况选择了Reinforcement Learning。
- 在这个图中红色的部分代表我们想要得到的输出,Regression表示我们希望得到是一些数值,比如说是对于房产价格的预测,或者是找出RTT,初始缓冲峰值速率和初始缓冲时延之间的关系… Classification表示我们想要对已知的信息进行分类,例如我们想要区分一个邮件是不是一个垃圾邮件,或者是给海量的新闻打上类别的标签。而Structured Learning希望得到的则是更加复杂的输出,比如说人脸识别中人脸的位置,这里希望得到的输出显然不是一个数字,也不是一个离散的类别。(对于Structured Learning我的理解还不是很清楚,就不多写了。等到学习了实际的例子有了更加深入的了解之后再来更新)。
- 图中绿色的部分是我们解决问题使用的方法,有线性模型,深度学习…之类的方法。我们根据需要去选择不同的方法也就是模型来解决我们的问题。
特征缩放
在对较多的参数进行梯度下降求最优参数的时候,我们一般会对数据进行特征缩放,将所有数据的范围映射到一个相同的范围内。视频和书告诉我们这样做有利与梯度下降时寻找最有的参数,但是这是为什么呢?假设我们现在有两个参数x1,x2,他们可能的假设函数是这样的$$y=b+w_1x_1+w_2x_2$$如果和的大小差距很大,的取值远大于,如图所示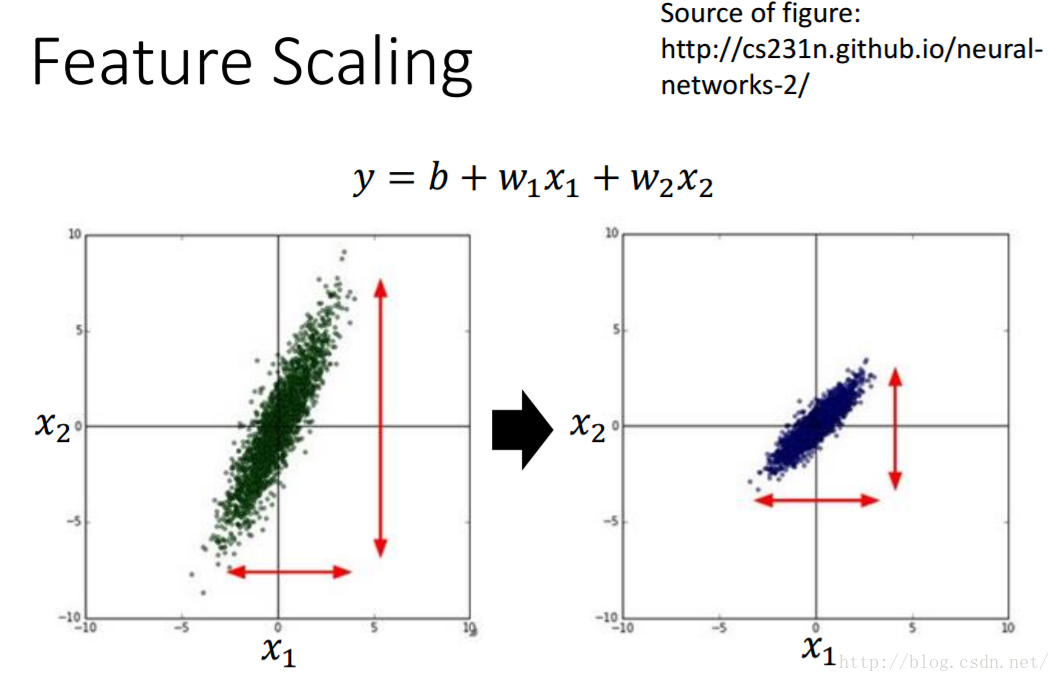
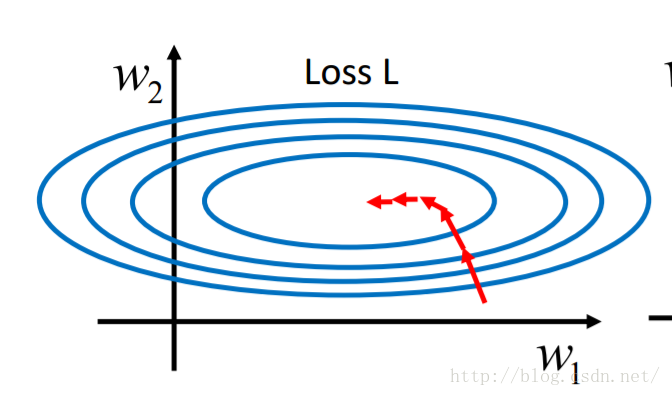
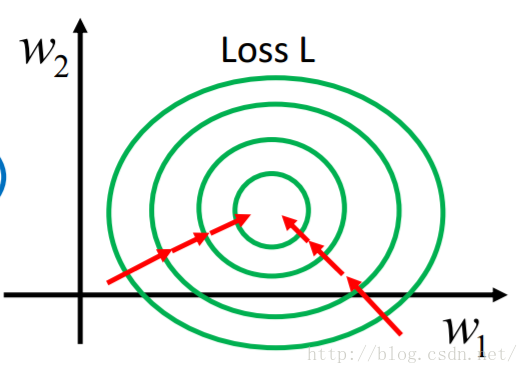
因为的取值特别大所以只需要有很小的变化就会引起有很大的变化,正好相反。同理根据loss function的公式可以知道很小的变化会引起loss function较大的变化。所以画出来和loss function的等高图就如下图所示,这条轴上的变化比这条轴上的变化剧烈的多,整个图形呈现出椭圆形。而经过特征缩放后的等高图则更像一个个同心圆。那么为什么同心圆比椭圆要好一些呢?其实从梯度下降的路径我们就可以看出一些东西。上面这个图的路径是弯曲的走向最优解,而下面这个是直接走向最优解。这是因为梯度下降的每一步都是向当前位置下降最快的地方进行的,也就是沿着等高线的法线方向进行。
误差的来源
在我们进行使用模型进行预测的时候会有误差的存在,那么误差的来源是什么呢?误差主要由两个部分组成:bias+variance。关于bais和variance的解释,感觉知乎上的一位答主写的比较好。大家可以去看一下这里是原文的链接:https://www.zhihu.com/question/27068705。下面是原文中的一张图,感觉比较形象的描述了这个问题。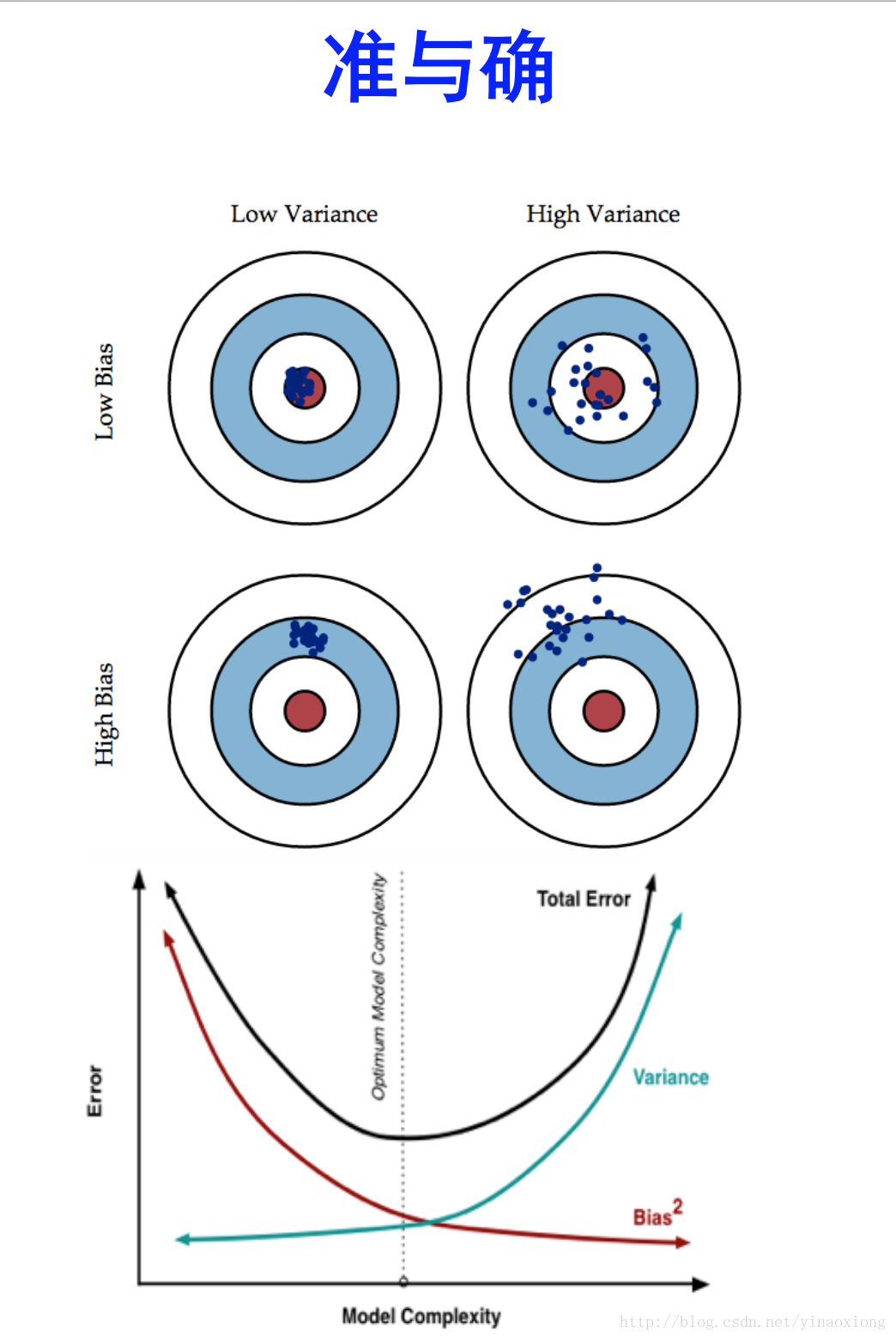
总的来说感觉是这样的:
- bias反映的是模型和样本数据的拟合程度。bais越小说明模型和样本数据的拟合程度越高。
- variance反映就是用样本数据训练好的模型在测试数据中的表现。而variance越小说明模型的泛化能力越强更具有通用性,测试数据会和样本数据得到类似的结果偏差不会太大。
这个理解的方式和李宏毅的视频中的解释有点点不一样,在李宏毅的视频中。
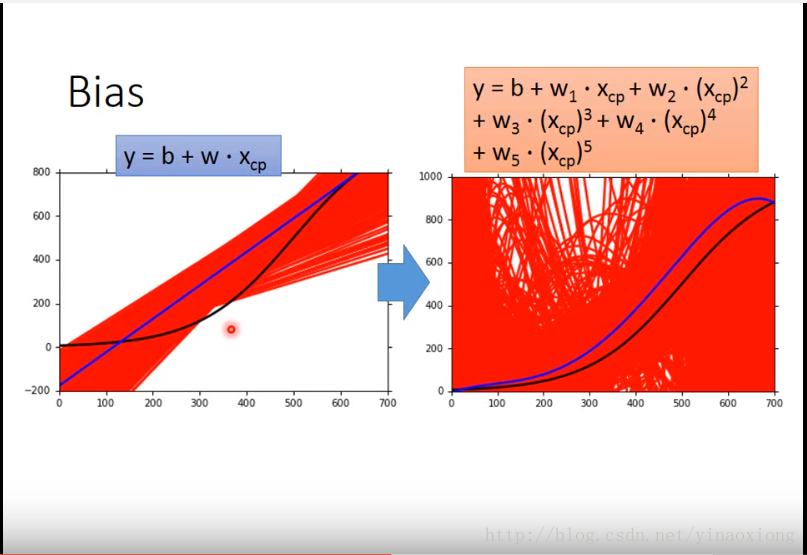
- bias指的是训练得到的模型的期望值和理想的模型之间的差距。也就是图中蓝色的线条和黑色的线条之间的差距。一般而言复杂的模型bias易班比较小,如图5次的黑线明显和理想的蓝线比较贴近。
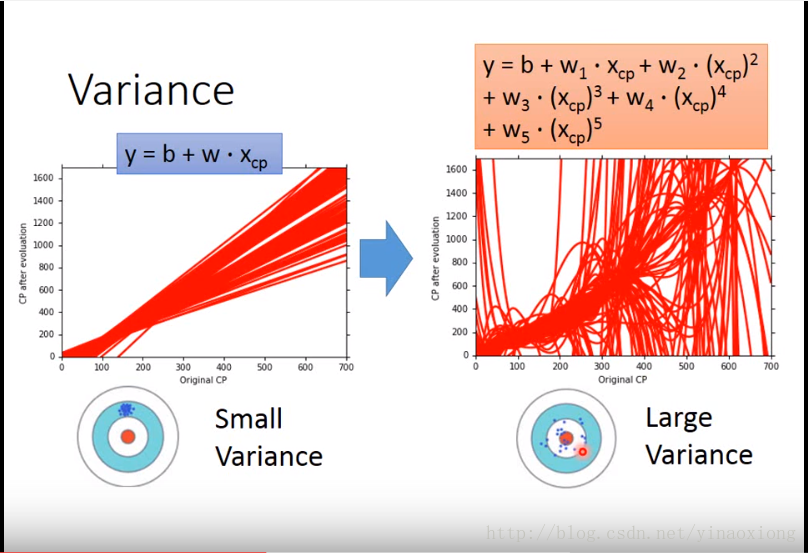
- variance是模型对数据的敏感程度,variance越低的模型对模型的敏感程度就越低。这样模型的通用性就好一些。一般而言简单的模型的variance要小一些,复杂的要大一些。如下图所示5次的模型的variance明显比1次的要大。
那么为什么复杂模型的bias要小一些而简单模型的要大一些呢?因为模型越复杂那么它所能够表现的形式就越多就可以更贴近那个理想的模型,显然5次的多项式是可以表示一条直线的。
为什么简单模型的variance要小一些而复杂模型的要大一些呢?因为简单模型对数据没有复杂模型那么敏感,可以看到在上图中的很多次实验中,1次的直线长的都差不多都是那个样子,而5次的就各种各样了。视频中举了一个极端的例子,就是常函数,如果是一个常函数的话。那么模型就对数据完全不敏感,variance就是0了。
那么如何判断自己模型出错是受那种误差的影响呢?其实这个应该是比较简单的,如果出现了unfitting那么就是bias太大了,也就是模型连训练数据都拟合不好。如果出现了overfitting那么就是variance太大了,也就是在训练数据中拟合的特别好,在测试数据中结果比较差。
那么如何降低bias呢?
- 正如上面提到的可以通过提高模型的复杂度可以有效的增加bias。比如在多项式拟合中选用更高的次数。
- 在视频中还提到一个方法就是 Add more features as input,增加特征输入的种类。因为这个结果可能不止和你选择的特征有关,增加输入的特征的种类当然可以减小bias。
那么如何如何降低variance呢? - 最好的方法应该就是增加数据的输入量了(这应该也就是大数据的魅力所在吧)。通过增加数据量,那些大量的正确的数据就会降低错误的数据对复杂模型的影响,模型也就越接近理想的模型了。
- 但是现实生活中我们往往找不到那么多数据,这个时候就需要正则化的帮助了。(这里我理解的还不是很好,以后再来补充吧)。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 协议 ,转载请注明出处!