复现《Region Filling and Object Removal by Exemplar-Based Image Inpainting》
论文内容
这篇论文是图片补全传统算法中的经典之作,主要的思路还是使用被扣图片剩余部分的冗余信息对孔洞进行填充。作者提出了一种确定区域填充顺序的方法,使得原有图片的结构信息得以更好的传播。论文的主要流程如下所示:
- 查找孔洞的边缘,计算边缘像素点的填充优先级
- 挑选出优先级最高的点,根据像素点得到像素块
- 在剩余部分查找和像素块最相似的像素块
- 用最佳像素块填充对应的部分填充对应的孔洞部分,查看填好了没有,没有跳到1
可以看到流程主要又两个方面:1 计算边缘像素点的优先级;2 查找最佳匹配块。下面来介绍一下这两个部分是怎么做的。
优先级的计算
在介绍之前先放一张论文中的图片方便之后的解释:
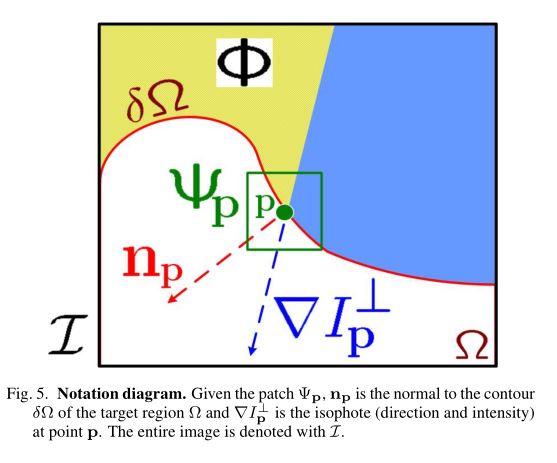
优先级的计算由下面的公式给出:
其中为像素点的信誉度(confidence),计算公式如下:
这个公式表明算法会优先填充周围信息比较丰富的像素点,因为这些点填充起来较为容易,填充得到的也更加的可靠,这样从周围最可靠的部分开始填充逐步向内推进使得整体的填充结果可靠。在开始的时候也就表现为优先考虑填充那个尖锐的突出部分。
另一个部分在论文中叫做data term(原谅我不知道应该怎么翻译😂),计算公式如下:
其中是归一化因子,如果是灰度图像的话就为255。这个公式又表示什么含义呢?通过这个公式我们可以发现算法会优先挑选哪些在原有图片结构附近的像素进行填充,这样的话图片原有的结构就可以更好的向着孔洞中延伸了。为什么要这样子呢?这是基于我们生活的关于图片一个常识,一般来说在图片较小的一片区域内它的主要结构是近似于直线的。
查找最佳匹配
这个部分就比较简单了,比较图片相似度的算法有很多作者挑选了一个最近简单最小平方和算法,然后全图暴力搜索最佳匹配。
实现中遇到的问题
在开始介绍之前首先放上一个自己实现的GitHub的地址:论文实现GitHub地址
开始不清楚边界上的法线和文中的 isophote 应该如何计算,之后发现边界上的发现不就是mask在边界上的梯度吗😂,而 isophote 不就是梯度旋转90度嘛。最后实现完成之后发现如下图的这样简单的图片填充得到的效果都惨不忍睹。

结果:

下面这些黑块是什么鬼。。。然后就看是什么原有啦,最后发现是查找最佳匹配的这个部分有问题,因为查找最佳匹配的时候是只看孔洞外面那个部分和剩余图片的匹配程度的。所以在圆形下面部分的图片块开始查找的时候会发现下原图中央边界部分的下面匹配的很好(虽然之后在全灰的部分也匹配的很好,但是在相同情况下先匹配的排到了前面),然后灾难就发生了。之后忘里面走回发现在全黑的部分匹配的最好,这就是下面这块黑东东出现的原因了。那么应该咋搞类。
在另外一个作者的参考实现中他加入了一个欧拉距离度,在相同情况下优先考虑比较近的图片块。这样做的原因可能是觉得图片的变化是渐进的,相近的图片块比较像吧。最后得到的结果如下所示:

看起来还是不错的。
从结构传播的这个角度来看,第一个结果为什么让人感到维和呢?因为它在填充的时候得到的最佳匹配的图片块的结构和原有的结构之间差距太大了,变化太剧烈了。这样我可以给它加上一个用于评估图片块和原有部分的结构相似度的部分应该得到更好的结果,改进后的公式如下所示:
其中为原有部分的最大梯度,为匹配图片块中的最大梯度,用于评估两个结构在方向上的相似性,而后面的这部分则是用于评估在变化剧烈程度上的相似性。最后得到的结果如下所示:

可以看到效果还是不错的。当然也可以尝试一下把这两种方法结合起来一下。之后我把跑了一下其他图片和有的图片的确效果还不错,有的就和论文有一些距离了😂。这些结果都可以在原始图片和结果都可以在GitHub中找到(填充结果),当然你也可以自己跑一遍。一些是一些实验结果:



和论文进行比较可以看到还有一些差距的。
总结
自动图片补全就像是人类看到图片脑补一样的,人类在脑补的时候会根据已有的常识(也就以前看过的类似图片)以及图片中的语义信息进行脑补,而这种方法还是只能使用较为有限的信息。同时在低频的时候补全效果较好,高频补全得到的效果较差。还有就是算法的效率较差,运算时间比较长。另外大家在自己制作mask的时候,可以考虑一下使用微软的paint 3D真的非常好用,先用神奇选择把要扣的东西扣出来(它有个自动补全背景可以和自己算法补全的结果比较一下),然后把扣下来的东西在Z轴上拉开,背景填充成黑色,扣下来的填充成白色保存成2D图片,一个mask就制作好了。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 协议 ,转载请注明出处!