SEQ2SQL:generating structured queries from natural language using reinforcement learning 论文翻译
摘要
Relational databases store a significant amount of the worlds data. However, accessing this data currently requires users to understand a query language such as SQL. We propose Seq2SQL, a deep neural network for translating natural language questions to corresponding SQL queries. Our model uses rewards from in the-loop query execution over the database to learn a policy to generate the query, which contains unordered parts that are less suitable for optimization via cross entropy loss. Moreover, Seq2SQL leverages the structure of SQL to prune the space of generated queries and significantly simplify the generation problem. In addition to the model, we release WikiSQL, a dataset of 80654 hand-annotated examples of questions and SQL queries distributed across 24241 tables from Wikipedia that is an order of magnitude larger than comparable datasets. By applying policybased reinforcement learning with a query execution environment to WikiSQL, Seq2SQL outperforms a state-of-the-art semantic parser, improving execution accuracy from 35.9% to 59.4% and logical form accuracy from 23.4% to 48.3%.
这个世界的很多数据被存储在关系型数据库中。但是,当前访问这些数据要求用户掌握数据库查询语言,例如SQL。我们提出了Seq2SQL,这是一个用于将自然语言问题转换为相应的SQL查询的深度神经网络。我们的模型使用在数据库中循环查询执行的奖励来学习生成查询的策略,该策略包含不适合通过交叉熵损失进行优化的无序部分。此外,Seq2SQL利用SQL的结构来修剪生成的查询的空间,并显着简化了生成问题。除了该模型外,我们还发布了WikiSQL,该数据库包含80654个手工标注的问题和SQL查询对分布在来自于维基百科的24241个表上,它比可比较的数据集大一个数量级。通过将带着查询执行环境的基于策略的强化学习应用在WikiSQL上,Seq2SQL的性能优于最先进的语义解析器,将执行精度从35.9%提高到59.4%,逻辑形式精度从23.4%提高到48.3%。
1 介绍
Relational databases store a vast amount of today’s information and provide the foundation of applications such as medical records (Hillestad et al., 2005), financial markets (Beck et al., 2000), and customer relations management (Ngai et al., 2009). However, accessing relational databases requires an understanding of query languages such as SQL, which, while powerful, is difficult to master. Natural language interfaces (NLI), a research area at the intersection of natural language processing and human-computer interactions, seeks to provide means for humans to interact with computers through the use of natural language (Androutsopoulos et al., 1995). We investigate one particular aspect of NLI applied to relational databases: translating natural language questions to SQL queries.
现如今关系型数据库存储了大量信息,并为诸如医疗记录(Hillestad等,2005),金融市场(Beck等,2000)和客户关系管理(Ngai等,2009)等应用奠定了基础。然而,访问关系数据库需要了解诸如SQL之类的查询语言,而查询语言虽然功能强大但难以掌握。自然语言接口(NLI)是自然语言处理与人机交互的交集处的研究领域,旨在为人类提供通过使用自然语言与计算机进行交互的手段(Androutsopoulos等,1995)。我们研究了NLI应用于关系数据库的一个特定方面:将自然语言问题转换为SQL查询。
Our main contributions in this work are two-fold. First, we introduce Seq2SQL, a deep neural network for translating natural language questions to corresponding SQL queries. Seq2SQL, shown in Figure 1, consists of three components that leverage the structure of SQL to prune the output space of generated queries. Moreover, it uses policy-based reinforcement learning (RL) to generate the conditions of the query, which are unsuitable for optimization using cross entropy loss due to their unordered nature. We train Seq2SQL using a mixed objective, combining cross entropy losses and RL rewards from in-the-loop query execution on a database. These characteristics allow Seq2SQL to achieve state-of-the-art results on query generation.
我们在这项工作中的主要贡献有两个方面。首先,我们介绍Seq2SQL,这是一个将自然语言问题转换为相应的SQL查询的深度神经网络。如图1所示,Seq2SQL由三个组件组成,这些组件利用SQL的结构来修剪生成的查询的输出空间。此外,它使用基于策略的强化学习(RL)来生成查询条件,由于其无序性质,这些条件不适合使用交叉熵损失进行优化。我们使用混合目标训练Seq2SQL,结合交叉熵损失和数据库中查询执行中的RL奖励。这些特性使Seq2SQL在生成查询结果时达到最先进水平。
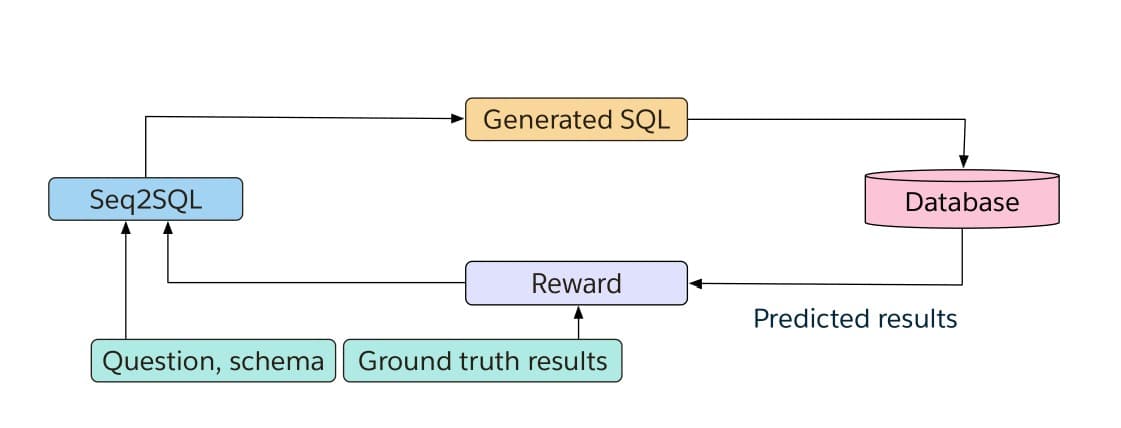
Figure 1: Seq2SQL takes as input a question and the columns of a table. It generates the corresponding SQL query, which, during training, is executed against a database. The result of the execution is utilized as the reward to train the reinforcement learning algorithm.
图1:Seq2SQL将问题和表的列作为输入。 它生成相应的SQL查询,在训练过程中,该查询针对数据库执行。 执行的结果被用作训练强化学习算法的奖励。
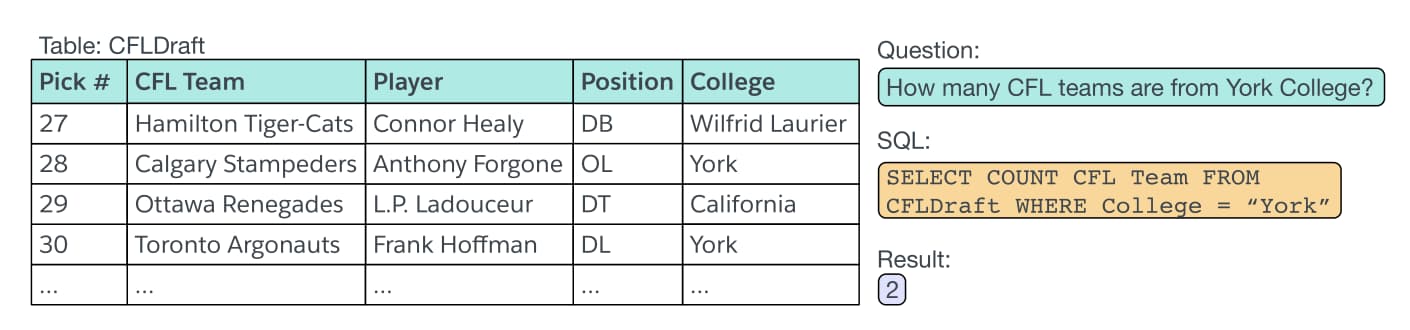
Figure 2: An example in WikiSQL. The inputs consist of a table and a question. The outputs consist of a ground truth SQL query and the corresponding result from execution.
图2:WikiSQL中的示例。 输入包括一个表格和一个问题。 输出包括SQL查询和相应的执行结果。
Next, we release WikiSQL, a corpus of 80654 hand-annotated instances of natural language questions, SQL queries, and SQL tables extracted from 24241 HTML tables from Wikipedia. WikiSQL is an order of magnitude larger than previous semantic parsing datasets that provide logical forms along with natural language utterances. We release the tables used in WikiSQL both in raw JSON format as well as in the form of a SQL database. Along with WikiSQL, we release a query execution engine for the database used for in-the-loop query execution to learn the policy. On WikiSQL, Seq2SQL outperforms a previously state-of-the-art semantic parsing model by Dong & Lapata (2016), which obtains 35.9% execution accuracy, as well as an augmented pointer network baseline, which obtains 53.3% execution accuracy. By leveraging the inherent structure of SQL queries and applying policy gradient methods using reward signals from live query execution, Seq2SQL achieves state-of-the-art performance on WikiSQL, obtaining 59.4% execution accuracy.
接下来,我们发布WikiSQL,这是一个80654个带批注的自然语言问题,SQL查询以及从Wikipedia的24241个HTML表中提取的SQL表实例的语料库。 WikiSQL比以前的语义解析数据集大一个数量级,以前的语义解析数据集提供逻辑形式以及自然语言。我们以原始JSON格式以及SQL数据库的形式发布WikiSQL中使用的表。与WikiSQL一起,我们发布了用于数据库的查询执行引擎,该数据库用于在循环中执行查询以学习该策略。在WikiSQL上,Seq2SQL的性能优于Dong&Lapata(2016)先前的最新语义解析模型,该模型可获得35.9%的执行准确度,以及增强的指针网络基线上,其可获得53.3%的执行准确度。通过利用SQL查询的固有结构并使用来自实时查询执行的奖励信号应用策略梯度方法,Seq2SQL在WikiSQL上实现了最先进的性能,获得59.4%的执行精度。
2 模型
The WikiSQL task is to generate a SQL query from a natural language question and table . Our baseline model is the attentional sequence to sequence neural semantic parser proposed by Dong & Lapata (2016) that achieves state-of-the-art performance on a host of semantic parsing datasets without using hand-engineered grammar. However, the output space of the softmax in their Seq2Seq model is unnecessarily large for this task. In particular, we can limit the output space of the generated sequence to the union of the table schema, question utterance, and SQL key words. The resulting model is similar to a pointer network (Vinyals et al., 2015) with augmented inputs. We first describe the augmented pointer network model, then address its limitations in our definition of Seq2SQL, particularly with respect to generating unordered query conditions.
WikiSQL的任务是根据自然语言问题和表模式生成SQL查询。我们的基线模型是Dong&Lapata(2016)提出的基于注意力的序列到序列语意解析模型,该模型在不使用人工语法的情况下,在大量语义解析数据集上实现了优良的性能。 但是,在此Seq2Seq模型中,softmax的输出空间对于此任务而言不必要地大。 特别是,我们可以将生成序列的输出空间限制为表模式,问题话语和SQL关键字的并集。 生成的模型类似于带有扩充输入的指针网络(Vinyals等,2015)。 我们首先描述增强指针网络模型,然后在我们对Seq2SQL的定义中解决其局限性,特别是在生成无序查询条件方面。
2.1 增强型指针网络
The augmented pointer network generates the SQL query token-by-token by selecting from an input sequence. In our case, the input sequence is the concatenation of the column names, required for the selection column and the condition columns of the query, the question, required for the conditions of the query, and the limited vocabulary of the SQL language such as SELECT, COUNT etc. In the example shown in Figure 2, the column name tokens consist of “Pick”, “#”, “CFL”, “Team” etc.; the question tokens consist of “How”, “many”, “CFL”, “teams” etc.; the SQL tokens consist of SELECT, WHERE, COUNT, MIN, MAX etc. With this augmented input sequence, the pointer network can produce the SQL query by selecting exclusively from the input.
增强指针网络通过从输入序列中进行选择来逐令牌生成SQL查询。 在我们的示例中,输入序列是查询的选择列和条件列所需的列名称,查询的条件,查询条件所必需的列名称以及SQL语言的有限词汇的串联 ,例如SELECT,COUNT等。在图2所示的示例中,列名称标记由“ Pick”,“#”,“ CFL”,“ Team”等组成; 问题标记由“How”,“many”,“ CFL”,“teams”等组成; SQL令牌由SELECT,WHERE,COUNT,MIN,MAX等组成。使用此扩展的输入序列,指针网络可以通过仅从输入中进行选择来生成SQL查询。
Suppose we have a list of N table columns and a question such as in Figure 2, and want to produce the corresponding SQL query. Let denote the sequence of words in the name of the jth column, where represents the ith word in the jth column and represents the total number of words in the jth column. Similarly, let and respectively denote the sequence of words in the question and the set of unique words in the SQL vocabulary.
假设我们有一个由N个表列组成的列表和一个如图2所示的问题,并想产生相应的SQL查询。 令表示第j列名称中的单词序列,其中 代表第j列中的第i个单词,代表第j列中的单词总数。 同样,让和 分别表示问题中的单词序列和SQL词汇表中的不重复单词集。
We define the input sequence x as the concatenation of all the column names, the question, and the
SQL vocabulary:
where [a;b] denotes the concatenation between the sequences a and b and we add sentinel tokens between neighbouring sequences to demarcate the boundaries.
我们将输入序列x定义为所有列名称,问题和SQL词汇:
其中[a; b]表示序列a和b之间的串联,我们在相邻序列之间添加标记标记以划定边界。
The network first encodes x using a two-layer, bidirectional Long Short-Term Memory network (Hochreiter & Schmidhuber, 1997). The input to the encoder are the embeddings corresponding to words in the input sequence. We denote the output of the encoder by , where is the state of the encoder corresponding to the tth word in the input sequence. For brevity, we do not write out the LSTM equations, which are described by Hochreiter & Schmidhuber (1997). We then apply a pointer network similar to that proposed by Vinyals et al. (2015) to the input encodings .
网络首先使用两层双向双向长短期记忆网络对x进行编码(Hochreiter和Schmidhuber,1997年)。 编码器的输入是与输入序列中的单词相对应的嵌入。 我们用表示编码器的输出,其中是与输入序列中第t个字相对应的编码器状态。 为简洁起见,我们没有写出Loch方程,Hochreiter&Schmidhuber(1997)对此进行了描述。 然后,我们应用类似于Vinyals等人提出的指针网络。 (2015)输入编码 。
The decoder network uses a two layer, unidirectional LSTM. During each decoder step s, the decoder LSTM takes as input , the query token generated during the previous decoding step, and outputs the state . Next, the decoder produces a scalar attention score for each position t of the input sequence:
We choose the input token with the highest score as the next token of the generated SQL query, .
解码器网络使用两层单向LSTM。 在每个解码器步骤s期间,解码器LSTM将在先前解码步骤期间生成的查询令牌作为输入,并输出状态。 接下来,解码器为输入序列的每个位置t生成标量注意力得分 :
我们选择得分最高的输入令牌作为生成的SQL查询的下一个令牌。
2.2 SEQ2SQL
While the augmented pointer network can solve the SQL generation problem, it does not leverage the structure inherent in SQL. Typically, a SQL query such as that shown in Figure 3 consists of three components. The first component is the aggregation operator, in this case COUNT, which produces a summary of the rows selected by the query. Alternatively the query may request no summary statistics, in which case an aggregation operator is not provided. The second component is the SELECT column(s), in this case Engine, which identifies the column(s) that are to be included in the returned results. The third component is the WHERE clause of the query, in this case WHERE Driver = Val Musetti, which contains conditions by which to filter the rows. Here, we keep rows in which the driver is “Val Musetti”.
尽管增强指针网络可以解决SQL生成问题,但它没有利用SQL固有的结构。 通常,如图3所示的SQL查询由三个组件组成。 第一个组件是聚合运算符,在本例中为COUNT,它生成查询选择的行的摘要。 或者,查询可以不请求摘要统计信息,在这种情况下,不提供聚合运算符。 第二个组件是SELECT列,在本例中为Engine,它标识要包含在返回结果中的列。 第三个组件是查询的WHERE子句,在本例中为WHERE Driver = Val Musetti,它包含过滤行的条件。 在这里,我们保留 driver 是 Val Musetti的行。
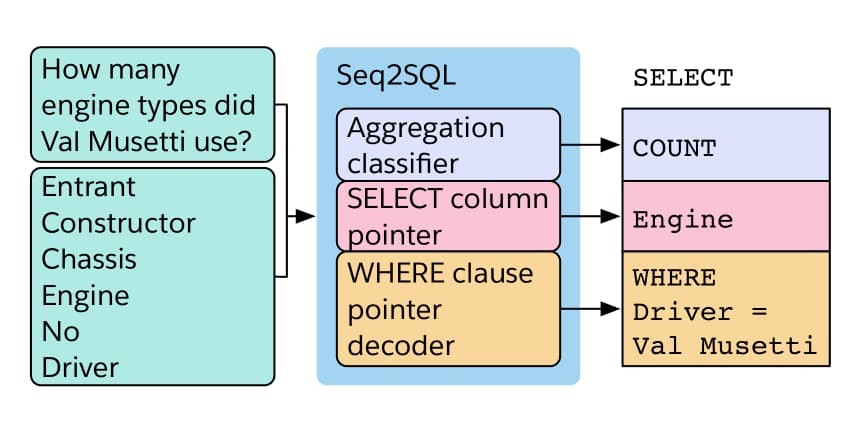
Figure 3: The Seq2SQL model has three components, corresponding to the three parts of a SQL query (right). The input to the model are the question (top left) and the table column names (bottom left).
图3:Seq2SQL模型具有三个组件,分别对应于SQL查询的三个部分(右)。 模型的输入是问题(左上方)和表列名称(左下方)。
Seq2SQL, as shown in Figure 3, has three parts that correspond to the aggregation operator, the SELECT column, and the WHERE clause. First, the network classifies an aggregation operation for the query, with the addition of a null operation that corresponds to no aggregation. Next, the network points to a column in the input table corresponding to the SELECT column. Finally, the network generates the conditions for the query using a pointer network. The first two components are supervised using cross entropy loss, whereas the third generation component is trained using policy gradient to address the unordered nature of query conditions (we explain this in the subsequent WHERE Clause section). Utilizing the structure of SQL allows Seq2SQL to further prune the output space of queries, which leads to higher performance than Seq2Seq and the augmented pointer network.
如图3所示,Seq2SQL具有三个部分,分别对应于聚合运算符,SELECT列和WHERE子句。 首先,网络对查询的聚合操作进行分类,并添加一个空操作,该操作对应于无聚合。 接下来,网络指向输入表中与SELECT列相对应的列。 最后,网络使用指针网络生成查询条件。 前两个组件使用交叉熵损失进行监督,而第三个组件使用策略梯度进行训练以解决查询条件的无序性质(我们将在后续的WHERE子句部分中对此进行说明)。 利用SQL的结构,Seq2SQL可以进一步修剪查询的输出空间,从而导致性能比Seq2Seq和增强指针网络更高。
Aggregation Operation. The aggregation operation depends on the question. For the example shown in Figure the correct operator is COUNT because the question asks for “How many”. To compute the aggregation operation, we first compute the scalar attention score, for each th token in the input sequence. We normalize the vector of scores to
produce a distribution over the input encodings, The input representation is the sum over the input encodings weighted by the normalized scores
Let denote the scores over the aggregation operations such as COUNT, MIN, MAX, and the no-aggregation operation NULL. We compute by applying a multi-layer perceptron to the input representation
We apply the softmax function to obtain the distribution over the set of possible aggregation operations We use cross entropy loss for the aggregation operation.
聚合操作 聚合操作取决于问题。 如图3所示,正确的运算符为COUNT,因为该问题询问“how many”。 为了计算聚合操作,我们首先为输入序列中的每个第t个令牌计算标量注意力得分。 我们对得分向量进行归一化,从而在输入编码上产生分布,。 输入表示是输入编码的总和,由标准化分数加权:
令表示聚合操作的得分,例如COUNT,MIN,MAX和无聚合操作为NULL。 我们通过一个多层感知机输入 来计算:
我们应用softmax函数来获取可能的聚合操作集上的分布 。 我们将交叉熵损失用于聚合操作。
SELECT Column. The selection column depends on the table columns as well as the question. Namely, for the example in Figure “How many engine types” indicates that we need to retrieve the “Engine” column. SELECT column prediction is then a matching problem, solvable using a pointer: given the list of column representations and a question representation, we select the column that best matches the question.
In order to produce the representations for the columns, we first encode each column name with a LSTM. The representation of a particular column is given by:
Here, denotes the the encoder state of the th column. We take the last encoder state to be column 's representation.
To construct a representation for the question, we compute another input representation using the same architecture as for (Equation 3 ) but with untied weights. Finally, we apply a multi-layer perceptron over the column representations, conditioned on the input representation, to compute the a score for each column
We normalize the scores with a softmax function to produce a distribution over the possible SELECT columns For the example shown in Figure the distribution is over the columns “Entrant”, “Constructor”, “Chassis”, “Engine”, “No”, and the ground truth SELECT column “Driver”. We train the SELECT network using cross entropy loss
选择列。选择列取决于表列以及问题。换句话说,对于图3中的示例,“多少种发动机类型”表示我们需要检索“引擎”列。 SELECT列预测是一个匹配问题,可以使用指针解决:给定列表示形式和问题表示形式的列表,我们选择与问题最匹配的列。
为了产生列的表示,我们首先使用一个LSTM编码列名。一个特定的列的表示由以下公式计算得出:
在这里,表示第j列的编码器状态。 我们将最后一个编码器状态设为作为j列的表示
为了构造问题的表示形式,我们计算另一个输入表示形式使用与(公式3)相同的架构,但权重不固定。 最后,我们在列表示上应用一个多层感知机用于约束输入表示去为每一个列j计算机一个分数:
我们使用softmax函数对分数进行归一化,用以在可能的SELECT列上产生分布 。 如图3所示,这个分布分布在
列“ Entent”,“ Constructor”,“ Chassis”,“ Engine”,“ No”和正确的SELECT列
“Driver”上。 我们使用交叉熵损失训练SELECT网络。
WHERE Clause. We can train the WHERE clause using a pointer decoder similar to that described in Section However, there is a limitation in using the cross entropy loss to optimize the network: the WHERE conditions of a query can be swapped and the query yield the same result. Suppose we have the question "which males are older than and the queries SELECT name FROM insurance WHERE age > 18 AND gender = “male” and SELECT name FROM insurance WHERE gender = “male” AND age, Both queries obtain the correct execution result despite not having exact string match. If the former is provided as the ground truth, using cross entropy loss to supervise the generation would then wrongly penalize the latter. To address this problem, we apply reinforcement learning to learn a policy to directly optimize the expected correctness of the execution result (Equation).
Instead of teacher forcing at each step of query generation, we sample from the output distribution to obtain the next token. At the end of the generation procedure, we execute the generated SQL query against the database to obtain a reward. Let denote the sequence of generated tokens in the WHERE clause. Let denote the query generated by the model and denote the ground truth query corresponding to the question. We define the reward as
The loss, , is the negative expected reward over possible WHERE clauses. We derive the policy gradient for as shown by Sutton et al. (2000) and Schulman et al. (2015) .
Here, denotes the probability of choosing token during time step In equation 10 , we approximate the expected gradient using a single Monte-Carlo sample .
where子句。 我们可以使用类似于2.1节中描述的指针解码器来训练获得WHERE子句。 但是,使用使用交叉熵损失来优化这个网络存在局限:一个查询的where限制可以在交换后依然产生相同的结果。 假设我们有一个问题“哪些男性年龄大于18岁”,然后查询语句为“SELECT name FROM insurance WHERE age > 18 AND gender =“male””和“SELECT name FROM insurance WHERE gender = “male” AND age > 18”。尽管没有完全匹配的字符串,但两个查询都获得了正确的执行结果。 如果
前者是作为正确的答案来提供的,使用交叉熵损失来监督生成会错误地惩罚后者。 为了解决这个问题,我们将强化学习应用于学习直接优化执行结果的预期正确性的策略(公式7)。
代替在查询生成的每个步骤中强制教育它,我们从输出分布采样到获取下一个令牌。 在生成过程结束时,我们执行生成的SQL查询针对数据库获取奖励。 令表示生成的序列WHERE子句。 令 表示模型生成的查询,而 表示与问题相对应的正确查询。 我们将奖励 定义为:
损失,是对可能的WHERE子句的预期负回报。
我们推导了的策略梯度,如Sutton(2000)和Schulman(2015)等人所示。
在此,表示在时间步长t期间选择令牌的概率。 在等式10中,我们使用单个蒙特卡洛样本y近似估计期望的梯度。
Mixed Objective Function. We train the model using gradient descent to minimize the objective function $ L = L^{agg} + L^{sel} + L^{whe}$. Consequently, the total gradient is the equally weighted sum of the gradients from the cross entropy loss in predicting the SELECT column, from the cross entropy loss in predicting the aggregation operation, and from policy learning.
混合目标函数。 我们使用梯度下降训练模型以最小化目标函数。 因此,总梯度是预测SELECT列中的交叉熵损失,预测聚合操作中的交叉熵损失以及策略学习得到的梯度的加权平均。
3 WikiSQL
WikiSQL is a collection of questions, corresponding SQL queries, and SQL tables. A single example in WikiSQL, shown in Figure 2, contains a table, a SQL query, and the natural language question corresponding to the SQL query. Table 1 shows how WikiSQL compares to related datasets. Namely, WikiSQL is the largest hand-annotated semantic parsing dataset to date - it is an order of magnitude larger than other datasets that have logical forms, either in terms of the number of examples or the number of tables. The queries in WikiSQL span over Figure 4: Distribution of questions in WikiSQL. a large number of tables and hence presents an unique challenge: the model must be able to not only generalize to new queries, but to new table schema. Finally, WikiSQL contains realistic data extracted from the web. This is evident in the distributions of the number of columns, the lengths of questions, and the length of queries, respectively shown in Figure 5. Another indicator of the variety of questions in the dataset is the distribution of question types, shown in Figure 4
WikiSQL是问题,相应的SQL查询和SQL表的集合。 WikiSQL中的一个示例(如图2所示)包含一个表,一个SQL查询以及与该SQL查询相对应的自然语言问题。表1显示了WikiSQL如何与相关数据集进行比较。就是说,WikiSQL是迄今为止最大的人工注释语义分析数据集-无论从示例数量还是在表数量上,它都比其他具有逻辑形式的数据集大一个数量级。 WikiSQL中的查询跨越图4:WikiSQL中的问题分布。拥有大量的表提出了一个独特的挑战:该模型不仅必须能够推广到新的查询,而且还能够推广到新的表架构。最后,WikiSQL包含从网上提取的真实数据。如图5所示,这在列数,问题的长度和查询的长度的方面得到了体现。在数据集中另一个问题多样性的指标是问题种类的分布,如图4所示。
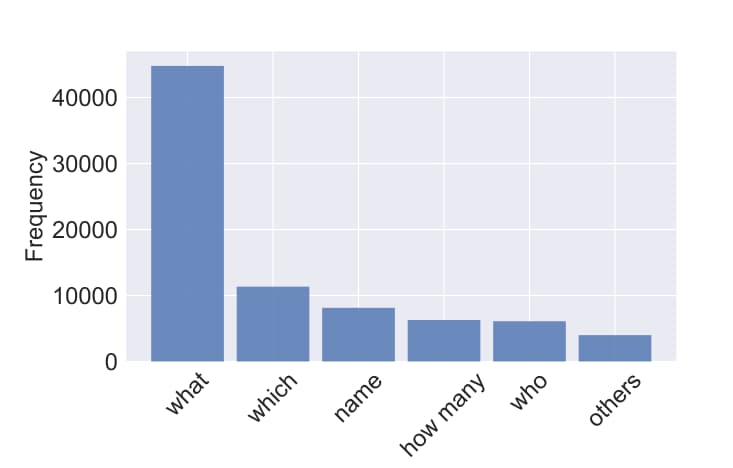
Figure 4: Distribution of questions in WikiSQL.
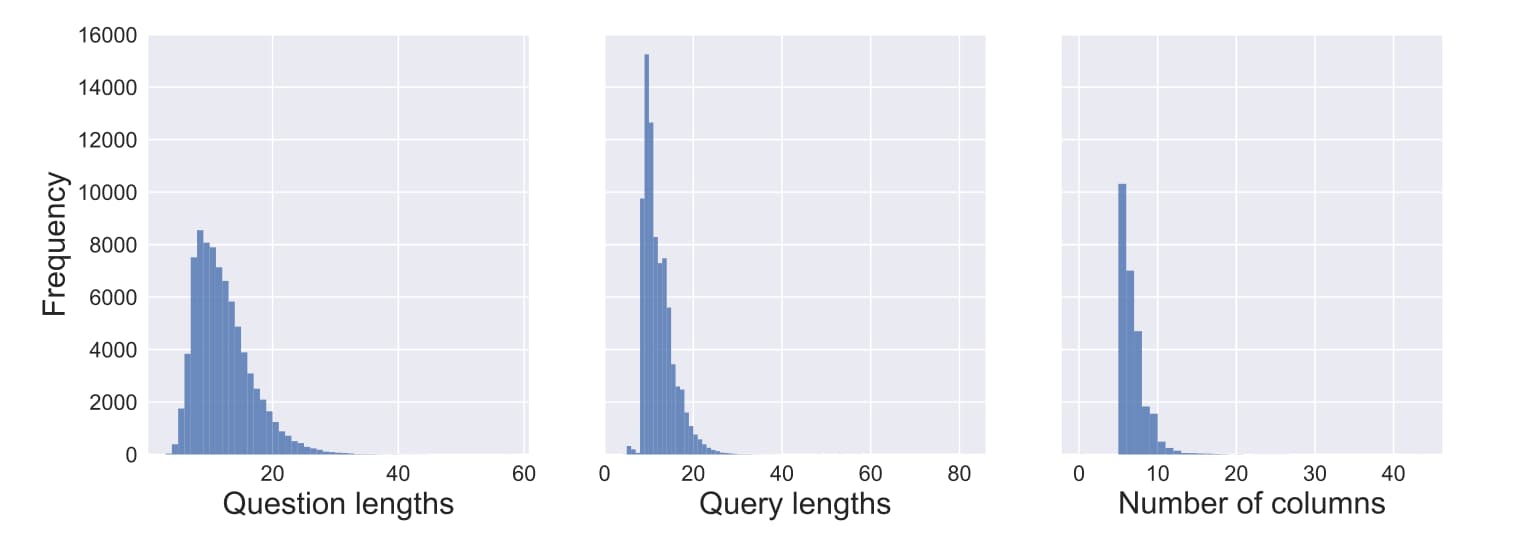
Figure 5: Distribution of table, question, query sizes in WikiSQL.
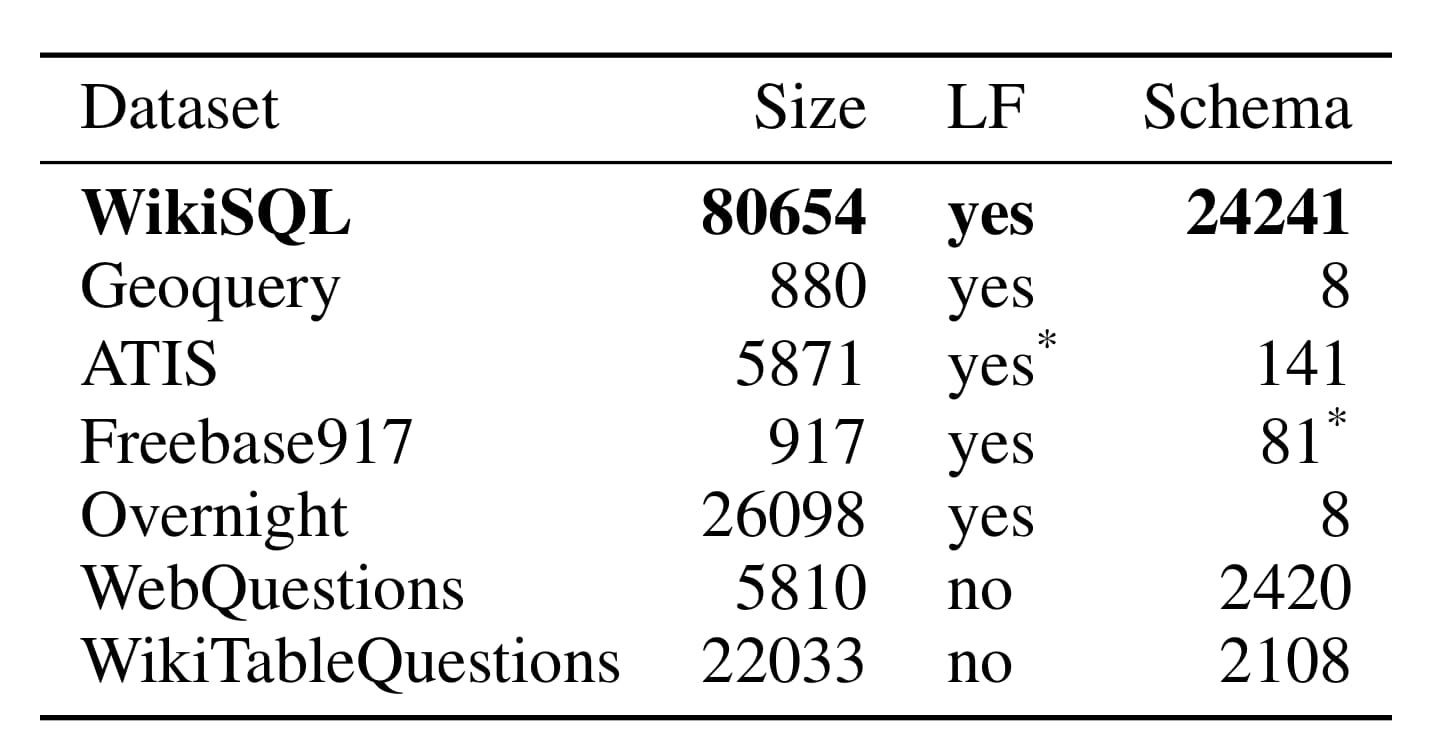
Table 1: Comparison between WikiSQL and existing datasets. The datasets are GeoQuery880 (Tang & Mooney, 2001), ATIS (Price, 1990), Free917 (Cai & Yates, 2013), Overnight (Wang et al., 2015), WebQuestions (Berant et al., 2013), and WikiTableQuestions (Pasupat & Liang, 2015). “Size” denotes the number of examples in the dataset. “LF” indicates whether it has annotated logical forms. “Schema” denotes the number of tables. ATIS is presented as a slot filling task. Each Freebase API page is counted as a separate domain.
表1:WikiSQL与现有数据集之间的比较。 数据集是GeoQuery880(Tang&Mooney,2001),ATIS(Price,1990),Free917(Cai&Yates,2013),Overnight(Wang等人,2015),WebQuestions(Berant等人,2013)和WikiTableQuestions (Pasupat&Liang,2015)。 “大小”表示数据集中的示例数。 “ LF”指示其是否具有注释的逻辑形式。 “模式”表示表的数量。 ATIS是作为插槽填充任务呈现的。 每个Freebase API页面均被视为一个单独的域。
We collect WikiSQL by crowd-sourcing on Amazon Mechanical Turk in two phases. First, a worker paraphrases a generated question for a table. We form the generated question using a template, filled using a randomly generated SQL query. We ensure the validity and complexity of the tables by keeping only those that are legitimate database tables and sufficiently large in the number of rows and columns. Next, two other workers verify that the paraphrase has the same meaning as the generated question. We discard paraphrases that do not show enough variation, as measured by the character edit distance from the generated question, as well as those both workers deemed incorrect during verification. Section A of the Appendix contains more details on the collection of WikiSQL. We make available examples of the interface used during the paraphrase phase and during the verification phase in the supplementary materials. The dataset is available for download at https://github.com/salesforce/WikiSQL.
我们分两个阶段通过在Amazon Mechanical Turk上众包来收集WikiSQL。 首先,一个工作人员解码为表格生成的问题。 我们使用模板形成生成的问题,并使用随机生成的SQL查询填充该模板。 通过仅保留那些合法数据库表且行和列数足够大的表,我们确保了表的有效性和复杂性。 接下来,另外两名工作人员验证释义与所生成问题的含义相同。 我们丢弃了没有表现出足够变化的释义,这些释义是通过与所生成问题的字符编辑距离来衡量的,以及那些在验证过程中被认为不正确的释义。 附录A部分包含有关WikiSQL集合的更多详细信息。 我们在补充材料中提供了在复述阶段和验证阶段使用的接口示例。 该数据集可从https://github.com/salesforce/WikiSQL下载。
The tables, their paraphrases, and SQL queries are randomly slotted into train, dev, and test splits, such that each table is present in exactly one split. In addition to the raw tables, queries, results, and natural utterances, we also release a corresponding SQL database and query execution engine.
这些表,其释义和SQL查询被随机分配到train,dev和test拆分中,以便每个表恰好存在于一个拆分中。 除了原始表,查询,结果和自然话语外,我们还发布了相应的SQL数据库和查询执行引擎。
3.1 评估
Let N denote the total number of examples in the dataset, the number of queries that, when executed, result in the correct result, and the number of queries has exact string match with the
ground truth query used to collect the paraphrase. We evaluate using the execution
accuracy metric . One downside of is that it is possible to construct a SQL query that does not correspond to the question but nevertheless obtains the same result. For example, the two queries SELECT COUNT(name) WHERE SSN = 123 and SELECT COUNT(SSN) WHERE SSN = 123 produce the same result if no two people with different names share the SSN 123. Hence, we also use the logical form
accuracy . However, as we showed in Section 2.2, incorrectly penalizes queries that achieve the correct result but do not have exact string match with the ground truth query. Due to these observations, we use both metrics to evaluate the models.
令N表示数据集中的示例总数,表示查询执行时可得出正确的结果数,表示查询语句与真实查询语句匹配的数量。 我们使用执行精度进行评估。的一个缺点是可以构造一个不对应于该问题但仍获得相同结果的SQL查询。 例如,如果没有两个不同名称的人共享SSN 123,则两个查询SELECT COUNT(name)WHERE SSN = 123和SELECT COUNT(SSN)WHERE SSN = 123会产生相同的结果。因此,我们也使用逻辑形式
精度。 但。但是,正如我们在2.2节中所示,错误地惩罚了达到正确结果但与地面真值查询不完全匹配的查询。 由于这些观察,我们使用两种指标来评估模型。
4 实验
We tokenize the dataset using Stanford CoreNLP (Manning et al., 2014). We use the normalized tokens for training and revert into original gloss before outputting the query so that generated queries are executable on the database. We use fixed GloVe word embeddings (Pennington et al., 2014) and character n-gram embeddings (Hashimoto et al., 2016). Let denote the GloVe embedding and the character embedding for word x. Here, is the mean of the embeddings of all the character n-grams in x. For words that have neither word nor character embeddings, we assign the zero vector. All networks are run for a maximum of 300 epochs with early stopping on dev split execution accuracy. We train using ADAM (Kingma & Ba, 2014) and regularize using dropout (Srivastava et al., 2014). All recurrent layers have a hidden size of 200 units and are followed by a dropout of 0.3. We implement all models using PyTorch. To train Seq2SQL, we first train a version in which the WHERE clause is supervised via teacher forcing (i.e. the policy is not learned from scratch) and then continue training using reinforcement learning. In order to obtain the rewards described in Section 2.2, we use the query execution engine described in Section 3.
我们使用Stanford CoreNLP标记数据集(Manning等,2014)。我们使用归一化的令牌进行训练,并在输出查询之前恢复为原始光泽,以便生成的查询在数据库上可执行。我们使用固定的GloVe词嵌入(Pennington等,2014)和字符n-gram嵌入(Hashimoto等,2016)。让表示GloVe嵌入,表示单词x的字符嵌入。在此,是所有字符n-gram在x中嵌入的平均值。对于既没有单词也没有字符嵌入的单词,我们指定零向量。所有网络最多可以运行300轮,并根据验证集上的执行精度使用早停法。我们使用ADAM进行训练(Kingma&Ba,2014),并使用dropout进行正则化(Srivastava等,2014)。所有循环图层的隐藏大小为200个单位,后接概率为0.3的dropout层。我们使用PyTorch实现所有模型。为了训练Seq2SQL,我们首先训练一个版本,其中WHERE子句通过数据进行监督学习(即未从头开始学习策略),然后继续使用强化学习进行训练。为了获得第2.2节中描述的奖励,我们使用第3节中描述的查询执行引擎。
4.1 结果
We compare results against the attentional sequence to sequence neural semantic parser proposed by Dong & Lapata (2016). This model achieves state of the art results on a variety of semantic parsing datasets, outperforming a host of non-neural semantic parsers despite not using hand-engineered grammars. To make this baseline even more competitive on our new dataset, we augment their input Reducing the output space by utilizing the augmented pointer network improves upon the baseline by 17.4%. Leveraging the structure of SQL queries leads to another improvement of 3.8%, as is shown by the performance of Seq2SQL without RL compared to the augmented pointer network. Finally, training using reinforcement learning based on rewards from in-the-loop query executions on a database leads to another performance increase of 2.3%, as is shown by the performance of the full Seq2SQL model.
我们将结果与Dong & Lapata (2016)提出的基于注意力的序列到序列神经语言分析模型进行比较。 该模型在各种语义解析数据集上都达到了先进的结果,尽管不使用手工设计的语法,但仍胜过许多非神经语义解析器。 为了使该基线在我们的新数据集上更具竞争力,我们增加了他们的输入通过利用增强的指针网络减少了输出空间,与基线相比提高了17.4%。 与增强指针网络相比,利用SQL查询的结构可以进一步提高3.8%,如不使用强化学习的Seq2SQL的性能所表明的。 最后,基于数据库中循环查询执行奖励的强化学习训练可以使性能再提高2.3%,如完整Seq2SQL模型的性能所示。
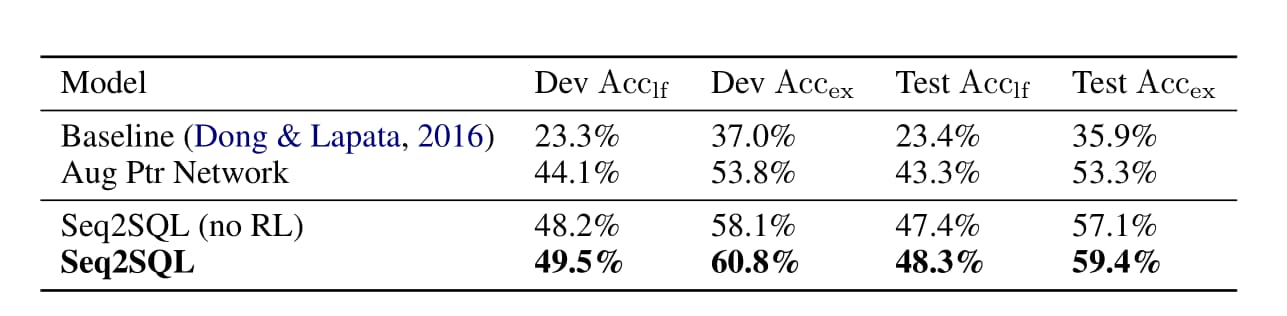
Table 2: Performance on WikiSQL. Both metrics are defined in Section 3.1. For Seq2SQL (no RL), the WHERE clause is supervised via teacher forcing as opposed to reinforcement learning. with the table schema such that the model can generalize to new tables. We describe this baseline in detail in Section 2 of the Appendix. Table 2 compares the performance of the three models.
表2:WikiSQL的性能。 这两个指标均在第3.1节中定义。 对于Seq2SQL(无RL),WHERE子句是通过数据监督学习得到而不是强化学习来监督的。表模式,以便模型可以推广到新表。 我们将在附录的第2节中详细描述此基准。 表2比较了这三种模型的性能。
4.2 分析
Limiting the output space via pointer network leads to more accurate conditions. Compared to the baseline, the augmented pointer network generates higher quality WHERE clause. For example, for “in how many districts was a successor seated on march 4, 1850?”, the baseline generates the condition successor seated = seated march 4 whereas Seq2SQL generates successor seated = seated march 4 1850. Similarly, for “what’s doug battaglia’s pick number?”, the baseline generates Player = doug whereas Seq2SQL generates Player = doug battaglia. The conditions tend to contain rare words (e.g. “1850”), but the baseline is inclined to produce common words in the training corpus, such as “march” and “4” for date, or “doug” for name. The pointer is less affected since it selects exclusively from the input.
通过指针网络限制输出空间可导致更精确的条件。 与基线相比,增强指针网络生成更高质量的WHERE子句。 例如,对于“in how many districts was a successor seated on march 4, 1850??”,基线生成条件:后继者seated = seated march 4 ,而Seq2SQL生成后继者seated = seated march 4 1850。类似的,对于“what’s doug battaglia’s pick number”,基线生成Player = doug,而Seq2SQL生成Player = doug battaglia。 条件通常包含稀有单词(例如“ 1850”),但是基线倾向于在训练语料库中生成常见单词,例如日期为“ march”和“ 4”,名称为“ doug”。 指针受的影响较小,因为它专门从输入中选择。
Incorporating structure reduces invalid queries. Seq2SQL without RL directly predicts selection and aggregation and reduces invalid SQL queries generated from 7.9% to 4.8%. A large quantity of invalid queries result from column names – the generated query refers to selection columns that are not present in the table. This is particularly helpful when the column name contain many tokens, such as “Miles (km)”, which has 4 tokens. Introducing a classifier for the aggregation also reduces the error rate. Table 3 shows that adding the aggregation classifier improves the precision, recall, and F1 for predicting the COUNT operator. For more queries produced by the different models, please see Section 3 of the Appendix.
合并结构可减少无效查询。 没有RL的Seq2SQL可直接预测选择和聚合,并将生成的无效SQL查询从7.9%减少到4.8%。 列名导致大量无效查询–生成的查询引用了表中不存在的选择列。 当列名包含许多标记(例如“ Miles(km)”,其中有4个标记)时,这特别有用。 为聚合引入分类器还可以降低错误率。 表3显示,添加聚合分类器可提高预测COUNT运算符的精度,召回率和F1。 有关不同模型产生的更多查询,请参阅附录的第3节。
| Model | Precision | Recall | F1 |
|---|---|---|---|
| Aug Ptr Network | 66.3% | 64.4% | 65.4% |
| Seq2SQL | 72.6% | 66.2% | 69.2% |
Table 3: Performance on the COUNT operator.
RL generates higher quality WHERE clause that are ordered differently than ground truth. Training with policy-based RL obtains correct results in which the order of conditions is differs from the ground truth query. For example, for “in what district was the democratic candidate first elected in 1992?”, the ground truth conditions are First elected = 1992 AND Party = Democratic whereas Seq2SQL generates Party = Democratic AND First elected = 1992. When Seq2SQL is correct and Seq2SQL without RL is not, the latter tends to produce an incorrect WHERE clause. For example, for the rather complex question “what is the race name of the 12th round trenton, new jersey race where a.j. foyt had the pole position?”, Seq2SQL trained without RL generates WHERE rnd = 12 and track = a.j. foyt AND pole position = a.j. foyt whereas Seq2SQL trained with RL correctly generates WHERE rnd = 12 AND pole position = a.j. foyt.
RL生成更高质量的WHERE子句,其顺序与事实不同。 使用基于策略的RL进行训练可获得正确的结果,其中条件的顺序与正确查询不同。 例如,对于“ in what district was the democratic candidate first elected in 1992?”,真实条件为:First elected = 1992 AND Party = Democratic,而Party = Democratic AND First elected = 1992。当Seq2SQL是正确的且Seq2SQL 如果没有RL,则RL往往会产生不正确的WHERE子句。 例如,对于一个相当复杂的问题,“what is the race name of the 12th round trenton, new jersey race where a.j. foyt had the pole position?”,未经RL训练的Seq2SQL生成WHERE rnd = 12 and track = a.j. foyt AND pole position = a.j. foyt,而经过RL训练的Seq2SQL正确生成WHERE rnd = 12 AND pole position = a.j. foyt。
相关工作
Semantic Parsing. In semantic parsing for question answering (QA), natural language questions are parsed into logical forms that are then executed on a knowledge graph (Zelle & Mooney, 1996; Wong & Mooney, 2007; Zettlemoyer & Collins, 2005; 2007). Other works in semantic parsing focus on learning parsers without relying on annotated logical forms by leveraging conversational logs (Artzi & Zettlemoyer, 2011), demonstrations (Artzi & Zettlemoyer, 2013), distant supervision (Cai & Yates, 2013; Reddy et al., 2014), and question-answer pairs (Liang et al., 2011). Semantic parsing systems are typically constrained to a single schema and require hand-curated grammars to perform well. Pasupat & Liang (2015) addresses the single-schema limitation by proposing the floating parser, which generalizes to unseen web tables on the WikiTableQuestions task. Our approach is similar in that it generalizes to new table schema. However, we do not require access to table content, conversion of table to an additional graph, nor hand-engineered features/grammar.
语义解析。在问答式语义解析(QA)中,自然语言问题被解析成逻辑形式,然后在知识图上执行(Zelle&Mooney,1996; Wong&Mooney,2007; Zettlemoyer&Collins,2005; 2007)。其他语义解析的工作重点是通过利用对话日志(Artzi&Zettlemoyer,2011),演示(Artzi&Zettlemoyer,2013),远程监督(Cai&Yates,2013; Reddy等, 2014年)和问答对(Liang等人,2011年)。语义解析系统通常被限制为单个模式,并且需要手工编写的语法才能很好地执行。 Pasupat&Liang(2015)通过提出浮动解析器解决了单一模式的局限性,该解析器泛化了WikiTableQuestions任务上看不见的Web表。我们的方法类似,因为它可以推广到新的表模式。但是,我们不需要访问表内容,也不需要将表转换为其他图形,也不需要手工设计的功能/语法。
Semantic parsing datasets. Previous semantic parsing systems were designed to answer complex and compositional questions over closed-domain, fixed-schema datasets such as GeoQuery (Tang & Mooney, 2001) and ATIS (Price, 1990). Researchers also investigated QA over subsets of largescale knowledge graphs such as DBPedia (Starc & Mladenic, 2017) and Freebase (Cai & Yates, 2013; Berant et al., 2013). The dataset “Overnight” (Wang et al., 2015) uses a similar crowdsourcing process to build a dataset of natural language question, logical form pairs, but has only 8 domains. WikiTableQuestions (Pasupat & Liang, 2015) is a collection of question and answers, also over a large quantity of tables extracted from Wikipedia. However, it does not provide logical forms whereas WikiSQL does. In addition, WikiSQL focuses on generating SQL queries for questions over relational database tables and only uses table content during evaluation.
语义解析数据集。 以前的语义解析系统被设计为在诸如GeoQuery(Tang&Mooney,2001)和ATIS(Price,1990)之类的封闭域,固定模式的数据集上回答复杂的组成问题。 研究人员还对诸如DBPedia(Starc&Mladenic,2017)和Freebase(Cai&Yates,2013; Berant等人,2013)之类的大规模知识图的子集进行了质量检查。 数据集“隔夜”(Wang等人,2015)使用类似的众包流程来构建自然语言问题,逻辑形式对的数据集,但只有8个域。 WikiTableQuestions(Pasupat&Liang,2015)是一个问题和答案的集合,也是从Wikipedia提取的大量表格中的。 但是,它不提供逻辑形式,而WikiSQL却提供。 此外,WikiSQL专注于针对关系数据库表生成问题的SQL查询,并且仅在评估期间使用表内容。
Representation learning for sequence generation. Dong & Lapata (2016)’s attentional sequence to sequence neural semantic parser, which we use as the baseline, achieves state-of-the-art results on a variety of semantic parsing datasets despite not utilizing hand-engineered grammar. Unlike their model, Seq2SQL uses pointer based generation akin to Vinyals et al. (2015) to achieve higher performance, especially in generating queries with rare words and column names. Pointer models have also been successfully applied to tasks such as language modeling (Merity et al., 2017), summarization (Gu et al., 2016), combinatorial optimization (Bello et al., 2017), and question answering (Seo et al., 2017; Xiong et al., 2017). Other interesting neural semantic parsing models are the Neural Programmer (Neelakantan et al., 2017) and the Neural Enquirer (Yin et al., 2016). Mou et al. (2017) proposed a distributed neural executor based on the Neural Enquirer, which efficiently executes queries and incorporates execution rewards in reinforcement learning. Our approach is different in that we do not access table content, which may be unavailable due to privacy concerns. We also do not hand-engineer model architecture for query execution and instead leverage existing database engines to perform efficient query execution. Furthermore, in contrast to Dong & Lapata (2016) and Neelakantan et al. (2017), we use policy-based RL in a fashion similar to Liang et al. (2017), Mou et al. (2017), and Guu et al. (2017), which helps Seq2SQL achieve state-of-the-art performance. Unlike Mou et al. (2017) and Yin et al. (2016), we generalize across natural language questions and table schemas instead of across synthetic questions on a single schema.
表示学习以生成序列。 Dong&Lapata(2016)的引人注目的序列神经语义解析器(我们以此为基准)尽管不利用手工语法,但仍在各种语义解析数据集上取得了最新的成果。与他们的模型不同,Seq2SQL使用类似于Vinyals等人的基于指针的生成实现更高的性能,尤其是在生成带有稀有词和列名的查询时。指针模型也已成功应用于语言建模(Merity等,2017),摘要(Gu等,2016),组合优化(Bello等,2017)和问题解答(Seo等)等任务,2017; Xiong等,2017)。其他有趣的神经语义解析模型是神经程序员(Neelakantan等,2017)和神经询问者(Yin等,2016)。 Mou等(2017)提出了一种基于神经询问器的分布式神经执行器,该执行器可以有效地执行查询并将执行奖励纳入强化学习中。我们的方法有所不同,因为我们不访问表内容,这可能是由于隐私问题而无法使用的。我们也不是手动设计模型架构来执行查询,而是利用现有的数据库引擎来执行有效的查询执行。此外,与Dong&Lapata(2016)和Neelakantan等人的研究相反,我们以类似于Liang、Mount、Guu等人的方式使用基于策略的RL,这有助于Seq2SQL实现最先进的性能。与Mou、Yin等人不同,我们对自然语言问题和表模式进行了概括,而不是对单个模式中的综合问题进行了概括。
Natural language interface for databases. One prominent works in natural language interfaces is PRECISE (Popescu et al., 2003), which translates questions to SQL queries and identifies questions that it is not confident about. Giordani & Moschitti (2012) translate questions to SQL by first generating candidate queries from a grammar then ranking them using tree kernels. Both of these approaches rely on high quality grammar and are not suitable for tasks that require generalization to new schema. Iyer et al. (2017) also translate to SQL, but with a Seq2Seq model that is further improved with human feedback. Seq2SQL outperforms Seq2Seq and uses reinforcement learning instead of human feedback during training.
数据库的自然语言接口。 自然语言接口中的一项杰出作品是PRECISE(Popescu等人,2003年),它可以将问题转换为SQL查询并识别出对其不确定的问题。 Giordani&Moschitti(2012)首先通过语法生成候选查询,然后使用树核对其进行排名,从而将问题转换为SQL。 这两种方法都依赖于高质量语法,并且不适合需要将其推广到新模式的任务。 Iyer等。 (2017)也转换为SQL,但使用了Seq2Seq模型,该模型可通过人工反馈得到进一步改进。 Seq2SQL优于Seq2Seq,并在训练过程中使用强化学习而不是人工反馈。
6 总结
We proposed Seq2SQL, a deep neural network for translating questions to SQL queries. Our model leverages the structure of SQL queries to reduce the output space of the model. To train Seq2SQL, we applied in-the-loop query execution to learn a policy for generating the conditions of the SQL query, which is unordered and unsuitable for optimization via cross entropy loss. We also introduced WikiSQL, a dataset of questions and SQL queries that is an order of magnitude larger than comparable datasets. Finally, we showed that Seq2SQL outperforms a state-of-the-art semantic parser on WikiSQL, improving execution accuracy from 35.9% to 59.4% and logical form accuracy from 23.4% to 48.3%.
我们提出了Seq2SQL,这是一种用于将问题转换为SQL查询的深度神经网络。 我们的模型利用SQL查询的结构来减少模型的输出空间。 为了训练Seq2SQL,我们应用了循环查询执行来学习生成SQL查询条件的策略,该策略无序且不适合通过交叉熵损失进行优化。 我们还引入了WikiSQL,它是一个问题和SQL查询的数据集,比可比较的数据集大一个数量级。 最后,我们证明Seq2SQL优于WikiSQL上最先进的语义解析器,将执行精度从35.9%提高到59.4%,逻辑形式精度从23.4%提高到48.3%。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 协议 ,转载请注明出处!